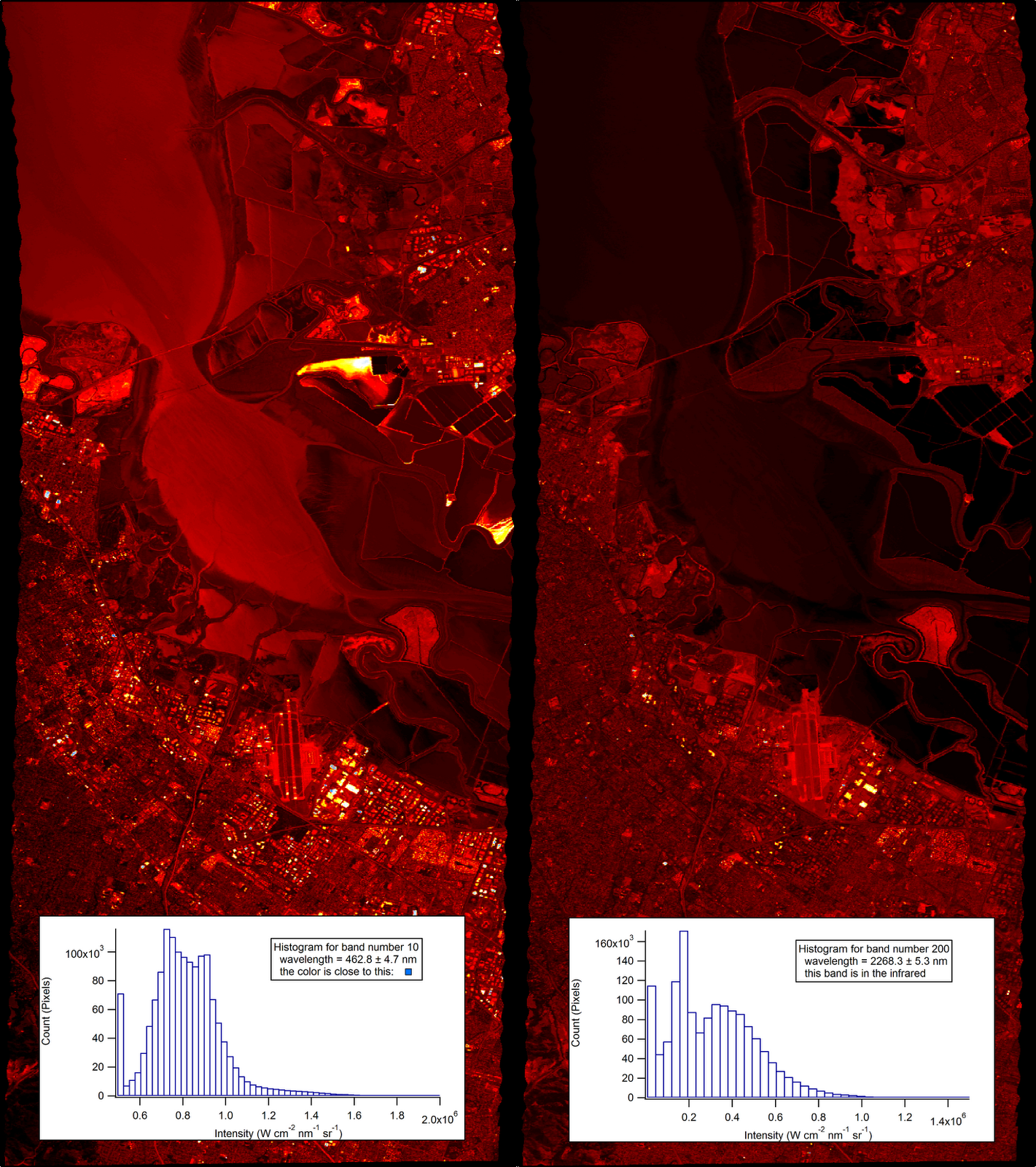
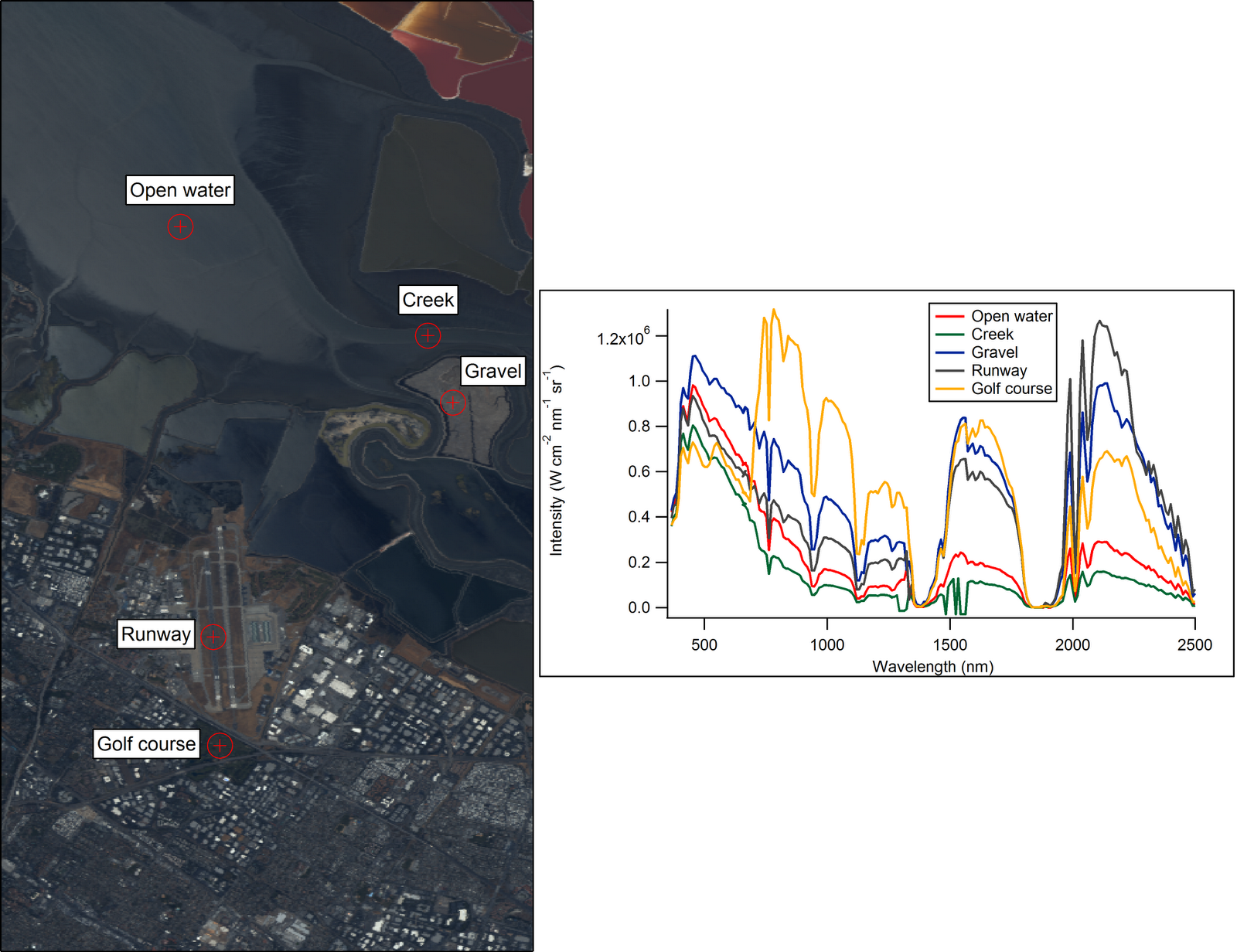
Life in the Infrared
 Corky, Matt, and Jared, with the experimental apparatus.
Corky, Matt, and Jared, with the experimental apparatus.
There's a place where TV remotes are flashlights, Wii's are torches, and
Snuggies are translucent. It's our kitchen. We modified a 3 dollar
webcam to view in the infrared portion of the electromagnetic spectrum.
We'll show you how, and what you can do with it. First, a little bit of
background. If you read the previous post by Alex, you'd know that
visible light waves are the same kind of waves as radio waves,
microwaves, and x-rays; they just wave at different frequencies. Light
that has a frequency just below what we can see is called "infrared",
which apparently derives from the latin infra--below red (thanks
wikipedia!). So we know that if we get an object hot enough, it will
glow visibly. However, warm objects (say, humans, cars, tanks) while not
emitting enough visible light to glow, will emit easily detectable
infrared light. This makes infrared imaging a handy technology for
finding warm things in the dark. And, since many opaque things in the
visible are transparent in the infrared (or vice versa), you can dream
up a lot of fun to be had if you could only see in the infrared. Well,
it turns out that the CCDs in many common webcams are sensitive to the
infrared (IR). However, since an infrared signal would make for a weird
looking visible light picture, it is simply filtered out. Well, we
(mostly Matt) got our hands on such a
webcam,
for a whopping 3 dollars, and removed the filter. Then we turned the
tables, and inserted a visible light filter. For this we used the
darkest part of a developed film roll, and while not getting rid of all
the visible, it did a pretty good job with the lights down low. You can
get a junk roll from your local Rite Aid photo center for free, just ask
for Sue. She is very helpful. So we took some pictures of whatever we
could find that was a strong IR source. It turns out that our particular
camera wasn't sensitive to detect the signal of a warm human (or a cold
one for that matter). We had to get something just a little hotter. So
we lit a stick on fire, and then blew it out. Here's what it looks like
in the now very pedestrian visible spectrum, with the lights out:
 It's just barely glowing. Now, let's look at it in what I'll call
"enhanced" visible with the lights on, meaning that it's sensitive to
both IR and visible at the same time.
It's just barely glowing. Now, let's look at it in what I'll call
"enhanced" visible with the lights on, meaning that it's sensitive to
both IR and visible at the same time.
 The infared obviously dominates the output. It looks like an IR
sparkler. Now, let's shut the lights off, and see only IR:
The infared obviously dominates the output. It looks like an IR
sparkler. Now, let's shut the lights off, and see only IR:
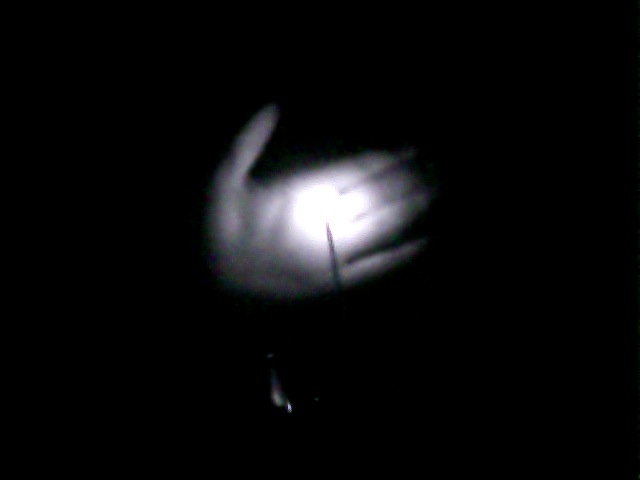 It's bright enough to "light up" my hand, which it certainly couldn't do
in the visible. Okay, so we had to light this thing on fire, and it was
already glowing. Well, my response to that is...this spoon:
It's bright enough to "light up" my hand, which it certainly couldn't do
in the visible. Okay, so we had to light this thing on fire, and it was
already glowing. Well, my response to that is...this spoon:
 Normal spoon. But actually we heated it up a bit on the stove. Here it
is in enhanced visible:
Normal spoon. But actually we heated it up a bit on the stove. Here it
is in enhanced visible:
 And now, lights off, infrared only:
And now, lights off, infrared only:
 Apparently we only heated up the tip significantly.
Now, we have a super high tech flashlight that has three modes. It can
produce green LED light, white LED light, or incandescent white light.
Corky pointed each one at me. White LED light, visible:
Apparently we only heated up the tip significantly.
Now, we have a super high tech flashlight that has three modes. It can
produce green LED light, white LED light, or incandescent white light.
Corky pointed each one at me. White LED light, visible:
 Creepy, eh? It's the shaved head.
Now, white LED light in the IR:
Creepy, eh? It's the shaved head.
Now, white LED light in the IR:
 Nuthin' doin'. Similarly for green LED light. This is included only for
its creepiness. First, in the visible:
Nuthin' doin'. Similarly for green LED light. This is included only for
its creepiness. First, in the visible:
 Corky calls this "the most palatable [pronounced incorrectly] picture of
Jared we could find." In the IR, nada:
Corky calls this "the most palatable [pronounced incorrectly] picture of
Jared we could find." In the IR, nada:
 But for incandescent white, in visible:
But for incandescent white, in visible:
 And IR:
And IR:
 I am aglow! Matt is clearly shocked. This happens because light
generated by LED's occurs because of electrons hopping around
semi-definite energy states of a material, making semi-definite
frequencies of light. However, incandescent light is due to the filament
being glowing hot, emitting radiation over a wide range of frequencies,
and we know that it's got a strong contribution in the IR.
So much for hot things. You have a bunch of IR dedicated sources around
your house that maybe you didn't know about. One such source is many TV
remote controls. Here we are, in the visible, with the lights low,
pointing remotes at our faces.
I am aglow! Matt is clearly shocked. This happens because light
generated by LED's occurs because of electrons hopping around
semi-definite energy states of a material, making semi-definite
frequencies of light. However, incandescent light is due to the filament
being glowing hot, emitting radiation over a wide range of frequencies,
and we know that it's got a strong contribution in the IR.
So much for hot things. You have a bunch of IR dedicated sources around
your house that maybe you didn't know about. One such source is many TV
remote controls. Here we are, in the visible, with the lights low,
pointing remotes at our faces.
 This is actually a promo pic for our 80's new wave band. Here's what
this looks like, with buttons depressed, in the IR:
This is actually a promo pic for our 80's new wave band. Here's what
this looks like, with buttons depressed, in the IR:
 A personal favorite.
These remotes weren't the brightest source we could find. It turns out
that the Wii sensor bar (which actually transmits, rather than receives
data) is a freakin' beacon (say that out loud). Here it is, on top of
our TV, which Corky is apparently flying towards.
A personal favorite.
These remotes weren't the brightest source we could find. It turns out
that the Wii sensor bar (which actually transmits, rather than receives
data) is a freakin' beacon (say that out loud). Here it is, on top of
our TV, which Corky is apparently flying towards.
 Unassuming little guy in the visible. But with the Wii on and in IR
mode:
Unassuming little guy in the visible. But with the Wii on and in IR
mode:
 There's a person in there too, IR bathing. But I promised you
translucent Snuggies. (Yes, we own a Snuggie, and highly recommend
them.) Here's Matt hiding behind one, whilst I angrily supervise:
There's a person in there too, IR bathing. But I promised you
translucent Snuggies. (Yes, we own a Snuggie, and highly recommend
them.) Here's Matt hiding behind one, whilst I angrily supervise:
 Now, let's look behind the curtain with IR:
Now, let's look behind the curtain with IR:
 Look, I told you it was a Snuggie, the sleeve is visible! Now, if we had
more resolution, we could even pick out a person in a dark room, and
look at the temperature variations of objects. However, with
approximately an hour of fiddling and 3 dollars, I think we did pretty
good. We're not hard to entertain, but this definitely did the trick.
Look, I told you it was a Snuggie, the sleeve is visible! Now, if we had
more resolution, we could even pick out a person in a dark room, and
look at the temperature variations of objects. However, with
approximately an hour of fiddling and 3 dollars, I think we did pretty
good. We're not hard to entertain, but this definitely did the trick.